
Fakt ist: Jede sechste Onlinebestellung geht zurück – und ein Teil davon landet im Müll. Mit Künstlicher Intelligenz (KI) und Data Science lassen sich clevere Modelle entwickeln, um Retouren zu minimieren. Das eröffnet zudem weitere Vorteile.
Der Onlinehandel boomt – und damit auch die Anzahl der Rücksendungen. Die Bundesregierung will daher Händler gesetzlich dazu verpflichten, entsprechende Waren, so weit wie möglich, erneut zu verkaufen oder wiederverwertbar zu machen. Damit soll verhindert werden, dass eigentlich noch hochwertige Artikel vernichtet werden, dies ist insbesondere im Onlinehandel üblich, um Platz in den Regalen zu schaffen oder weil zurückgesendete Artikel wegzuwerfen günstiger ist als sie erneut zu verkaufen.
Dieses Gesetz wird viele Online- und Versandhändler vor massive Probleme stellen. Grund genug, sich ein paar Gedanken zu dieser Thematik und deren Lösung zu machen.
Sehen wir uns zunächst ein typisches Retouren-Szenario aus dem Online- und Versandhandel an (fiktives Profil)
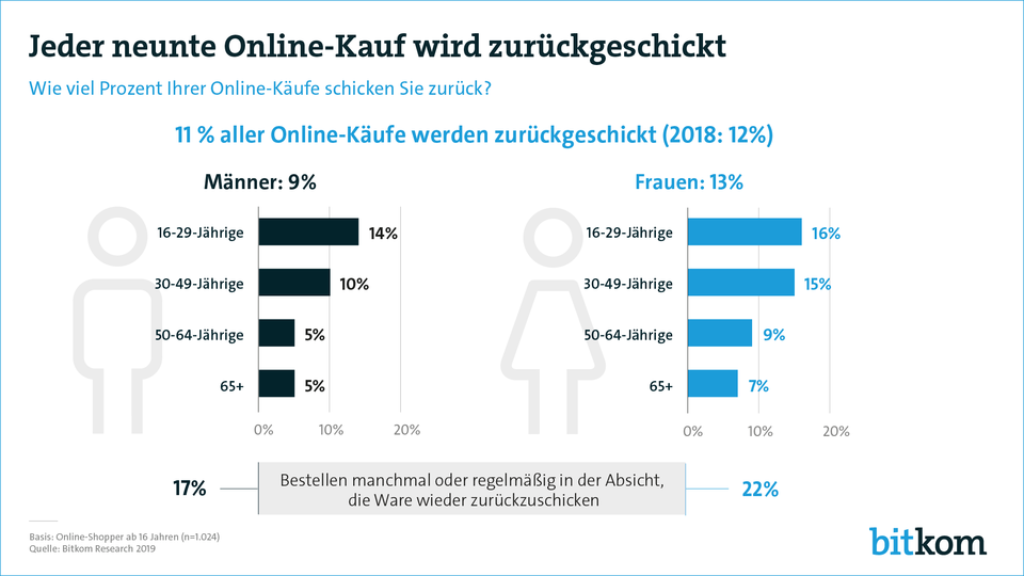
(Bildquelle: Bitkom 20220)
Ein Kunde, 39 Jahre alt, weiblich, verheiratet, lebt in einer Großstadt in Deutschland, hat ein Kind, besitzt einen höheren Bildungsabschluss, arbeitet als Teamleiterin im Marketing, wohnt in einem Reihenhaus, besitzt ein Auto, einen Hund, joggt gern und macht gelegentlich Yoga. Sie hat kürzlich im Onlinehandel zwei Sporthosen bestellt, eine hellgraue und eine schwarze, sowie ein paar Laufschuhe und eine Regenjacke für das Kind.
Als die Bestellung bei ihr daheim ankommt, stellt sie fest, dass
- die Schuhe wie angegossen passen,
- die Regenjacke zwar passt, aber die Farbe nicht ganz so ist wie sie auf dem Bild ausgesehen hat und
- eine der Sporthosen zu weit ist.
Eine der Sporthosen (hellgrau) und die Regenjacke schickt sie zurück.
Diese Sendung kommt nach ein paar Tagen beim Versandhaus als Retoure zurück und muss aufbereitet werden, um wieder in den Verkauf zu gelangen.
Für das Versandunternehmen stellen sich nun folgende Aufgaben bzw. auch Fragen
- Wie viele Retouren sind insgesamt pro Zeiteinheit und Periode zu erwarten?
- Welcher Art werden diese Retouren sein, d.h. was ist der Grund für den Rückversand und um welche Produkte geht es hauptsächlich?
- Wie hoch wird der Aufbereitungsaufwand sein?
- Welche Art von Bestellung bedingt welche Retouren (Art, Zustand, Menge)?
- Gibt es Kundenprofile, die besonders wenig, oder auch besonders viele Retouren ver-ursachen?
- Bei welchem Kundentyp habe ich mit welcher Art von Retoure und welcher Häufigkeit zu rechnen?
- Wie viele interne Ressourcen und Mitarbeiter muss ich wann und wie einsetzen, um diese Retouren aufzuarbeiten?
Kundenprofile auf Basis von Analysen und Modellen
Ein wesentlicher Baustein zur Lösung dieser Anforderungen sind Data-Science- und KI-Verfahren, die mit mathematisch-statistischen Methoden geeignete Vorhersagemodelle entwickeln. Aber auf was stützen sich nun die Analyse und Modellerstellung in der Praxis?
Vor allem auf historische Daten wie dem Bestellverhalten, historischen Kundentransaktionen, der Bestellhistorie und manchmal auch elektronischem Schriftverkehr (E-Mails oder soziale Medien). All diese Informationen werden mit einem geeigneten Algorithmus oder Verfahren des maschinellen Lernens zu einem oder mehreren Modellen verrechnet.
Diese Kundenmerkmale, über alle verfügbaren Kunden analysiert, können zu Profilen bzw. Modellen verarbeitet werden, mit denen sich oben genannte Fragen beantworten und abschätzen lassen. Um diese Profile bzw. Modelle anzulegen, können etwa folgende Kundeninformationen aufschlussreich sein:
- Alter: 39 Jahre bzw. Altersgruppe: 35 – 50 Jahre
- Geschlecht: weiblich
- Familienstand: verheiratet
- Wohnort: städtisch
- Kinder im Haushalt: ja
- Bildungsabschluss: Abitur mit anschließendem Fachstudium
- Beruf: leitende Angestellte
- Fachbereich: Marketing
- Hausbesitz: ja
- Auto: ja
- Haustier: ja
- Hobbies: Joggen und Yoga bzw. sportlich aktiv
Diese Merkmale und ihr oben erwähntes Bestellverhalten lassen vermuten, dass diese Kundin oft online einkauft und dabei drei bis fünf Artikel im Warenkorb liegen, von denen ca. 20 Prozent zurückgesendet werden.
Die Datenmenge macht‘s
Liegen diese Informationen für den Großteil des Kundenstamms und tagesaktuell vor, dann kann ein Data Scientist für die jeweiligen Profile Kategorien und darauf aufbauend Modelle entwickeln. Dies könnte zum Beispiel der Retourentyp (sendet nie/fast nie zurück, sendet häufig zurück, sendet fast immer zurück) sein, und/oder das Mengengerüst, also die Anzahl der zurückgesendeten Teile und der Aufbereitungssaufwand der Retouren.
Konkret gibt eine derartige Modellierung folgende Einblicke
- zeit- und saisonabhängige Vorhersagen zu den Mengengerüsten der zurückgesendeten Artikel
- tages- und wochenaktuelle Prognosen zu den benötigten Personalbedarfen
- typische Profile von Rücksendern
- Produkte und Produktkombinationen, welche besonders häufig zurückgesendet werden
- Aufwandsabschätzungen, die für die Aufbereitung und Wiederverwertung nötig sind
- kundenspezifische Affinitätsprofile
- gezieltes Kampagnenmanagement betreiben und
- Vorhersagen zur Kaufwahrscheinlichkeit bestimmter Produkte.
Mit diesen Informationen können anschließend geeignete Maßnahmen ergriffen und Strategien entwickelt werden, um Retouren zu vermeiden.
Das könnten im Einzelnen zum Beispiel detaillierte Produktbeschreibungen sein, die vom KI-Modell gesteuert werden oder maßgeschneiderte, profilspezifische Beratung im Kundencenter. Eine weitere Möglichkeit wäre bereits im Vorfeld, also bevor die Bestellung eingeht, Änderungen im Bezahlsystem bzw. den Bezahlmöglichkeiten vorzunehmen. Oder es werden Maßnahmen ergriffen, die „ungehemmtes“ Bestellverhalten regulieren.
Modelle vielfältig einsetzbar
Das Praktische ist, dass diese Modelle je nach Einsatzgebiet, bedarfsgerecht benutzt werden können. Das heißt etwa „händisch“ bei bestimmten Projekten, die einmalig oder periodisch anfallen. Möglich ist jedoch auch eine automatische Nutzung im Batchmodus auf Webseiten, die in Abhängigkeit der Modelle, dynamischen und personalisierten Inhalt aufbauen. Schließlich können sie auch im Rahmen der Kundenberatung bzw. Fallabwicklung in Call-Center-Applikationen zur Unterstützung der Agenten hinzugezogen werden.
Als Folge dieser Vorhersagen und Modellierungsmöglichkeiten ergeben sich verschiedene KPIs und zusätzlicher Mehrwert für das Unternehmen:
- Zeit- und Kostenersparnis in zahlreichen Geschäftsbereichen
- effizienter Personaleinsatz, bessere Planungsgrundlagen
- erhöhte Kundenzufriedenheit und Kundenloyalität wegen besserer Fallabwicklung
- oft höhere Wertschöpfung und erhöhte Verkaufspotenziale aufgrund besserer und perso¬nalisierter Kundenansprache.
Analyse und Modellerstellung geben Online- und Versandhändlern nicht nur umfassende Einblicke in das Bestellverhalten ihrer Kunden, sondern mit ihrer Hilfe lässt sich auch Retouren besser vorhersehen – und im Idealfall sogar ganz vermeiden. Unternehmen aus dem E-Commerce sollten daher die Möglichkeiten und Potenziale von Data Science und KI-Verfahren nutzen, um effektiv Kosten zu senken und einzusparen.
Autor: Dr. Christian Trippner arbeitet seit über 25 Jahren im Bereich Datenanalyse, Data Science und Modellbildung und ist derzeit Data Science Spezialist im Information Architecture Team der IBM Deutschland. Dort betreut er KI-Projekte für Kunden aus dem Bereich Consumer, Retail, Entwicklung & Produktion sowie Wissenschaft und Forschung.


